
This will be the first of several articles that provides details on Pyscript files and file systems. I will discuss the different virtual file systems and how to access files located on the desktop.
I have put each example in this article on my website. My examples can be downloaded using wget, curl , or by right-clicking on the page and selecting view page source. You can also right-click on the link and select Save link as.
Examples:
- Example 1 – Test file access #1
- Example 2 – Test file access #2
- Example 3 – Display a file from the local file system
- Example 4 – Display an image from the local file system
Part 2 of this series.
Terms:
-
Local File System
- This is the computer’s file system that the browser loads from. The browser security model prohibits web applications from directly accessing the local file system. Allowing direct access would be a serious security problem.
-
Virtual File System
- This is the file system that runs inside the browser. There are several types. The default type that is set up when a web page loads is transient. This means that any data stored in that file system is lost on page refresh. There are persistent file systems available for mounting.
Pyscript supports the Python Standard Library File and Directory APIs. These APIs access storage within the Virtual File System. The virtual file system is provided by Emscripten File System API. Pyscript maps the Python Standard Library File and Directory APIs onto the Emscripten File System API.
PyScript Boilerplate HTML
For this article, I will use the following boilerplate. In the examples, I will only include the parts between the <py-script> tags.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>File System Examples</title> <link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" /> <script defer src="https://pyscript.net/alpha/pyscript.js"></script> </head> <body> <py-script> </py-script> </body> </html> |
Accessing the Virtual File System
The first step is to understand the concept of the current working directory. This will be the default location where files created by a Python application are stored.
You can try this example on my website [link].
|
1 2 3 4 |
import os print('Current Working Directory:') print(os.getcwd()) |
The results of os.getcwd() are:
|
1 2 |
Current Working Directory: /home/pyodide |
What is pyodide? Pyodide (pie-o-dide) is the framework/library that PyScript is built upon. They chose to name the default directory /home/pyodide.
Let’s look at what is stored in the root directory /.
|
1 2 3 4 |
print('Root directory contents:') files = os.listdir('/') for file in files: print(file) |
Results:
|
1 2 3 4 5 6 |
Root directory contents: tmp home dev proc lib |
Interesting, that looks like a basic Linux system.
If we list the contents of the /dev directory, we will find some interesting files listed:
|
1 2 3 4 |
print('/dev directory contents:') files = os.listdir('/dev') for file in files: print(file) |
Results:
|
1 2 3 4 5 6 7 8 9 10 |
/dev directory contents: null tty tty1 random urandom shm stdin stdout stderr |
Let’s create a file in the current working directory. Then read the file and print the contents.
|
1 2 3 4 5 6 7 |
print('Create a file, read the file and print the contents:') f = open('testfile.txt', 'w') f.write('Hello PyScript World') f.close() f = open('testfile.txt', 'r') print(f.read()) f.close() |
Results:
|
1 2 |
Create a file, read the file and print the contents: Hello PyScript World |
Creating, writing, and reading normal files is easy to do. Experienced Python developers would improve the code so that file handles are closed automatically.
|
1 2 3 4 5 |
print('Create a file, read the file and print the contents:') with open('testfile.txt', 'w') as f: f.write('Hello PyScript World') with open('testfile.txt', 'r') as f: print(f.read()) |
Storage Quota
You might ask, how much storage space is available in this virtual file system? Browsers such as Chrome establish quotas for virtual file system usage. On my test system, I only have 128 GB free, but Chrome allows for 614 GB. The 614 GB is per origin. The quota is based upon total disk space and not free space. Each browser sets its own formula for storage quotas. Poorly designed web applications can abuse a browser’s file system.
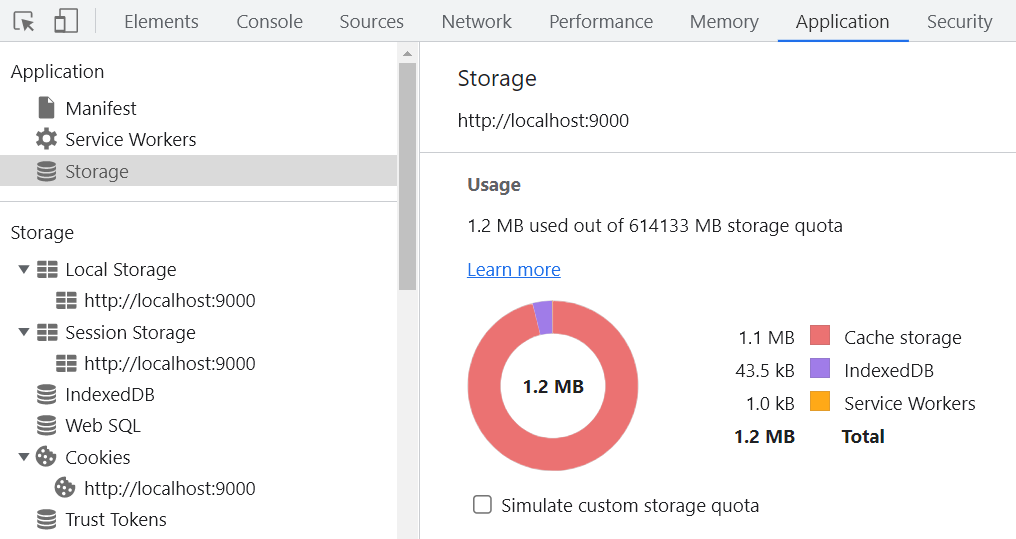
Link to Chrome documentation:
Chrome: Understanding storage quota
Storage Persistence
Let’s start with a new example. This time, we will list the content of the current directory and then check if filename.txt exists. If it does, display its contents. If not, then create it. This will test if a page refresh causes files to be lost.
You can try this example on my website [link].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import os from os.path import exists filename = 'filename.txt' print('Current directory contents:') files = os.listdir('.') if len(files) == 0: print('Directory is empty') else: for file in files: print(file) print('Check if file exists:') file_exists = exists(filename) if file_exists is True: print('File exists') print('Read the file and print the contents:') with open(filename, 'r') as f: print(f.read()) else: print('File does not exists') print('Create a file, read the file and print the contents:') with open(filename, 'w') as f: f.write('Hello PyScript World') with open(filename, 'r') as f: print(f.read()) |
Results:
|
1 2 3 4 5 6 |
Current directory contents: Directory is empty Check if file exists: File does not exists Create a file, read the file and print the contents: Hello PyScript World |
Refresh the page and the same results are displayed. Files are not persisted on page reloads.
Why is data not persisted? The default virtual file system is based upon FS.MEMFS. MEMFS is a memory file system. I will cover virtual file system types in Part 3.
What can you do if you want to store persistent data? This is an important feature that can improve web applications.
There are two options:
- Store persistent data in the local file system. I will discuss that in Part 2.
- Store persistent data in the virtual file system. I will cover that in Part 3 where I will introduce the FS API and the types of virtual file systems. One type (FS.IDBFS) is based upon IndexedDB which is persistent.
Reading files from the local file system
Accessing files on the local file system cannot be performed directly by Python or JavaScript applications. By directly I mean the application must request access from the browser which then displays the file browse dialog. This requires human interaction and is a security feature to prevent applications from accessing local files without the user’s permission.
A new feature that is in development could change how the local file systems are accessed. I am not covering the new feature as it is not a standard yet and is mostly Chrome specific. The new API requires a user’s approval but the API interaction is much better for the application. Read more about this new feature at this link:
The File System Access API: simplifying access to local files
The first step is to create an HTML element that the user can select to start the file selection process:
|
1 2 |
<label for="myfile">Select a file:</label> <input type="file" id="myfile" name="myfile"> |
That creates the standard HTML control similar to this screenshot:

Next, we need to wire up a Python function that will receive a callback when the user completes selecting a file after clicking the Choose File button. When the function process_file() is called, the event parameter contains information about the file that the user selected. This function proceeds and reads the file data from the browser.
There is one important package to import: asyncio. Without that package, you will see error messages in the browser console that are hard to understand. The key to remember is that the browser is asynchronous. That means we need to write callback functions with the async keyword.
|
1 2 3 4 5 6 7 8 9 10 |
import asyncio from js import document from pyodide import create_proxy async def process_file(event): fileList = event.target.files.to_py() for f in fileList: data = await f.text() document.getElementById("content").innerHTML = data |
Python functions cannot be called directly by the browser. A special proxy must be created. The browser calls the proxy which then calls the Python function. The proxy manages the translation of data types from the browser’s internal structure to ones Python understands and vice versa.
|
1 2 3 4 5 6 7 |
# Create a Python proxy for the callback function # process_file() is your function to process events from FileReader file_event = create_proxy(process_file) # Set the listener to the callback e = document.getElementById("myfile") e.addEventListener("change", file_event, False) |
Let’s put that into a complete example including HTML so that everything makes sense. You can try this example on my website [link].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>File System Examples</title> <link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" /> <script defer src="https://pyscript.net/alpha/pyscript.js"></script> </head> <body> <p>This example shows how to read a file from the local file system and display its contents</p> <br /> <p>Warning: Not every file type will display. PyScript removes content with tags such as XML, HTML, PHP, etc. Normal text files will work.</p> <br /> <p>No content type checking is performed to detect images, executables, etc.</p> <br /> <label for="myfile">Select a file:</label> <input type="file" id="myfile" name="myfile"> <br /> <br /> <div id="print_output"></div> <br /> <p>File Content:</p> <div style="border:2px inset #AAA;cursor:text;height:120px;overflow:auto;width:600px; resize:both"> <div id="content"> </div> </div> <py-script output="print_output"> import asyncio from js import document, FileReader from pyodide import create_proxy async def process_file(event): fileList = event.target.files.to_py() for f in fileList: data = await f.text() document.getElementById("content").innerHTML = data def main(): # Create a Python proxy for the callback function # process_file() is your function to process events from FileReader file_event = create_proxy(process_file) # Set the listener to the callback e = document.getElementById("myfile") e.addEventListener("change", file_event, False) main() </py-script> </body> </html> |
That example covers the basics of reading files from the local file system. There are more advanced details, but this will get you started. I recommend reading the documentation for the FileReader class. I will show another example, this one reads images from the local file system and displays them on a webpage. This demonstrates another FileReader API readAsDataURL(). You can try this example on my website [link].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>File System Examples</title> <link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" /> <script defer src="https://pyscript.net/alpha/pyscript.js"></script> </head> <body> <p> This example shows how to process a input file event and display the content as an image </p> <br /> <label for="myfile">Select a file:</label> <input type="file" id="myfile" name="myfile"> <br /> <br /> <p>Image:</p> <img id="image"> <py-script> import asyncio import js from js import document from pyodide import create_proxy def read_complete(event): # event is ProgressEvent # console.log('read_complete') image = document.getElementById("image"); image.src = event.target.result async def process_file(x): fileList = document.getElementById('myfile').files for f in fileList: # reader is a pyodide.JsProxy reader = js.FileReader.new() # Create a Python proxy for the callback function onload_event = create_proxy(read_complete) reader.onload = onload_event reader.readAsDataURL(f) return def setup(): # Create a Python proxy for the callback function file_event = create_proxy(process_file) # Set the listener to the callback e = document.getElementById("myfile") e.addEventListener("change", file_event, False) setup() </py-script> </body> </html> |
Summary
The examples in this article show how to access one type of the virtual file system (MEMFS) and how to read files from the local file system. I have not gone into advanced details on these methods. I will cover more advanced topics in the next parts of this series on Pyscript Files and File Systems.
More Information
- Other articles that I have written on PyScript
- Emscipten File System API
- Chrome: Understanding storage quota
- IndexedDB
- The File System Access API: simplifying access to local files
- FileReader
Photography Credit
I write free articles about technology. Recently, I learned about Pexels.com which provides free images. The image in this article is courtesy of Djalma Paiva Armelin at Pexels.

I design software for enterprise-class systems and data centers. My background is 30+ years in storage (SCSI, FC, iSCSI, disk arrays, imaging) virtualization. 20+ years in identity, security, and forensics.
For the past 14+ years, I have been working in the cloud (AWS, Azure, Google, Alibaba, IBM, Oracle) designing hybrid and multi-cloud software solutions. I am an MVP/GDE with several.
August 24, 2022 at 9:44 PM
Thanks a lot!