Google Service Account Credentials are available in two file formats: Json and P12. P12 is also known as PFX. The following code shows how to use P12 credentials to list the buckets in Google Cloud Storage without using an SDK.
Note: The P12 file format is deprecated. The Google recommended format is now Json.
You will need the Google Service Account Email address, Service Account Credentials in P12 format, the P12 password (defaults to notasecret) and your project Id (gcloud config list project)
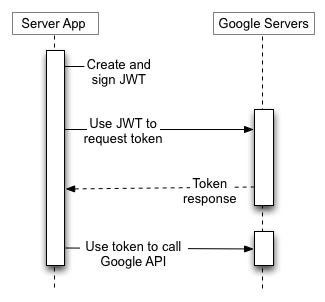
The P12 file is processed and the Private Key is loaded into memory to be used to sign a Json Web Token (JWT). This Signed-JWT (JWS) is then passed to a Google OAuth 2.0 endpoint to be exchanged for a Bearer Access Token. This token is then used in the HTTP Authorization header to authorize Google API calls.
The HTTP headers for a Google API request look like this:
|
1 2 3 |
Host: www.googleapis.com Authorization: Bearer + token Content-Type: application/json |
Example Python 3.x source code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
############################################################ # Version 1.00 # Date Created: 2018-12-21 # Last Update: 2018-12-21 # https://www.jhanley.com # Copyright (c) 2018, John J. Hanley # Author: John Hanley ############################################################ ''' List a project's buckets using a P12 Service Account Credentials. This code is written for Python 3.x and does not use the Google SDKs. https://developers.google.com/identity/protocols/OAuth2ServiceAccount#authorizingrequests ''' import json import time import jwt import httplib2 import requests import OpenSSL.crypto # Project ID for this request project = 'development-123456' # Create the HTTP url for the Google Storage REST API url = "https://www.googleapis.com/storage/v1/b?project=" + project # Google Endpoint for creating OAuth 2.0 Access Tokens from Signed-JWT auth_url = "https://www.googleapis.com/oauth2/v4/token" # Set how long this token will be valid in seconds expires_in = 3600 # Expires in 1 hour #scopes = "https://www.googleapis.com/auth/cloud-platform" scopes = "https://www.googleapis.com/auth/devstorage.read_only" # Details on the Google Service Account. The email must match the Google Console. sa_filename = 'compute-engine.p12' sa_password = 'notasecret' sa_email = '123456789012-compute@developer.gserviceaccount.com' def load_private_key(p12_path, p12_password): ''' Read the private key and return as base64 encoded ''' # print('Opening:', p12_path) with open(p12_path, 'rb') as f: data = f.read() # print('Loading P12 (PFX) contents:') p12 = OpenSSL.crypto.load_pkcs12(data, p12_password) # Dump the Private Key in PKCS#1 PEM format pkey = OpenSSL.crypto.dump_privatekey( OpenSSL.crypto.FILETYPE_PEM, p12.get_privatekey()) # return the private key return pkey def requestToken(p12_path, p12_password, p12_email, scope): ''' Create an AccessToken from a service account p12 credentials file ''' pkey = load_private_key(p12_path, p12_password) issued = int(time.time()) expires = issued + expires_in # expires_in is in seconds # Note: this token expires and cannot be refreshed. The token must be recreated # JWT Headers additional_headers = { "alg": "RS256", "typ": "JWT" # Google uses SHA256withRSA } # JWT Payload payload = { "iss": p12_email, # Issuer claim "sub": p12_email, # Issuer claim "aud": auth_url, # Audience claim "iat": issued, # Issued At claim "exp": expires, # Expire time "scope": scope # Permissions } # Encode the headers and payload and sign creating a Signed JWT (JWS) sig = jwt.encode(payload, pkey, algorithm="RS256", headers=additional_headers) # JWT Grant type params = { # JWT Bearer Token Grant Type Profile for OAuth 2.0 "grant_type": "urn:ietf:params:oauth:grant-type:jwt-bearer", "assertion": sig } # Call the Google Endpoint to create a Bearer Access Token r = requests.post(auth_url, data=params) #print(r.json()) if r.ok: return(r.json()['access_token'], '') return None, r.text token, err = requestToken(sa_filename, sa_password, sa_email, scopes) if token is None: print('Error: Cannot get credentials') print(err) exit(1) #print(url) # HTTP request headers headers = { "Host": "www.googleapis.com", "Authorization": "Bearer " + token, "Content-Type": "application/json" } h = httplib2.Http() resp, content = h.request(uri=url, method="GET", headers=headers) s = content.decode('utf-8').replace('\n', '') j = json.loads(s) print('') print('Buckets') print('----------------------------------------') for item in j['items']: print(item['name']) |

I design software for enterprise-class systems and data centers. My background is 30+ years in storage (SCSI, FC, iSCSI, disk arrays, imaging) virtualization. 20+ years in identity, security, and forensics.
For the past 14+ years, I have been working in the cloud (AWS, Azure, Google, Alibaba, IBM, Oracle) designing hybrid and multi-cloud software solutions. I am an MVP/GDE with several.
February 26, 2019 at 9:20 PM
With havin so much content do you ever run into any issues of plagorism
or copyright infringement? My website has a lot of completely unique
content I’ve either created myself or outsourced but it seems a lot
of it is popping it up all over the internet without my authorization.
Do you know any techniques to help stop content from being ripped off?
I’d truly appreciate it.
February 27, 2019 at 2:58 PM
The purpose of my blog is to share knowledge, so I don’t mind everyone linking to or sharing my content as long as I am credited.
I do not have specific advice to offer on plagiarism or copyright infringement. If you put something on the Internet and people like it or see value, it will be copied. Just a fact of life. I guess that you could create certain “special words or expressions” in your content and then Google search for those terms. If you find a site with your content, send them a polite letter to remove your content.
Writing articles, blogs, content, etc. is a labor of love. I don’t know how people make money doing this.